Stále se nacházíme v tématu zpěvů a zpěvových mikrofonů a minule jsme si pojmenovali možnosti korekčního nastavení při ozvučování lidského hlasu. Dnes si řekneme něco o kompresi signálu, který nám zpěvový mikrofon zprostředkovává.
Co se týče komprese zpěvu a vokálů, tak právě ty jsou jednou z nejčastěji komprimovaných součástí v hudbě. Souvisí to úzce s faktem, že zpěv je jako by to, co zpívanou nahrávku či živou produkci tak nějak „prodává“, a je tedy v jakémsi prvořadém obecném zájmu, aby byl slyšet vyrovnaně, a pokud možno pořád tam, kde slyšet být má. Pokud běžný amatérský posluchač nedokáže v mixu hudby přímo rozeznat a identifikovat např. baskytaru, pak zpěv rozezná a identifikuje skutečně v podstatě každý. :-) Na druhé straně, jak jsme si říkali např. u akustické kytary, je zpěv „položkou“, kde může být komprese i poměrně slyšitelná, až rušivá. Projevuje se to nejčastěji zvukově „plochým“ projevem, který postrádá většinu původní dynamiky, kdy zpěv zní ve všech polohách hlasu sice stejně a hlasitostně vyrovnaně, nicméně celkový dojem pak není příliš přirozený. Ve studiu se vokál velmi často s jistou dávkou komprese přímo natáčí už jenom kvůli tomu, že u některých dynamičtějších zpěvových partů by bylo takřka nemožné nastavit úroveň do záznamu tak, aby byl stále nějak použitelně slyšitelný, a přitom nám v hlasitých místech nepřebuzoval vstup do nahrávacího zařízení.

V dřívějších dobách, kdy většinově převažoval analogový záznam, nebylo přebuzení pásu až takovým problémem, naopak se tento jev často záměrně vyvolával (a to samozřejmě nejen u zpěvu) pro známý a oblíbený efekt analogové saturace. Při digitálním záznamu už musíme být opatrnější, přebuzení vstupu zvukové karty se nám projeví tzv. digitálním clippingem - lupanci, které, zvlášť pokud se jich v krátkém čase nasbírá značný počet blízko za sebou, nemusejí jít následně již s dobrým výsledkem zcela odstranit. Pokud si ve studiu zpěv s neúměrně vyšší mírou komprese již takto zaznamenáme, může se stát, že pak není možno s touto chybou následně nic moc extra smysluplného udělat a výsledek bude trpět značnou dávkou zmíněné nepřirozenosti. Samozřejmě vše souvisí s celkovou úlohou zpěvu v dané kapele a mixu v rámci daného stylu a žánru hudby. Jinou úroveň komprese nastavíme u metalového vokálu, kde naplno „hrnou zkreslené kytary“ a do podobného frekvenčního pásma musíme zpěvovou stopu „zapasovat“, jinou třeba při jazzovém šansonu, kde lehce v pozadí ševelí hudba a nad ní volně „proplouvá“ zpěv využívající všech dynamicko-pocitových rejstříků. Běžnou praxí bývá, že se při natáčení nastaví jakási mírná komprese (řekněme, abychom např. zabránili přebuzení vstupu ve špičkách) a nahraná stopa se následně při mixu dle aktuální potřeby ještě „dokomprimuje“. Samozřejmě - v rámci různých stylů a žánrů - bude většinou značně jiný už samotný vokální projev jako takový, co se hlasové techniky týče.
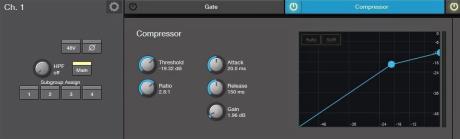
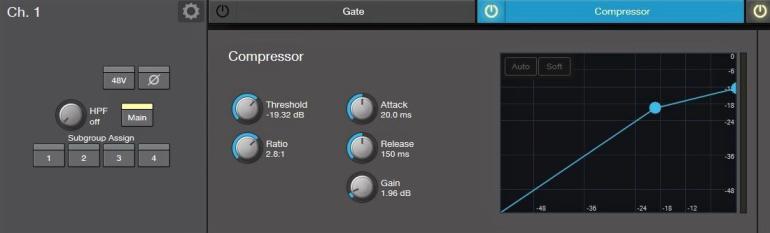
Při live akcích pochopitelně víceméně odpadají výše zmíněné studiové atributy, vše se odehrává jednou - „teď a tady“ - a naším úkolem je vše nějak rozumně nastavit, když už ne na první dobrou, tak alespoň na druhou či třetí dobrou. :-) Při zvukové zkoušce tedy zkusme zařadit nejprve menší až střední míru komprese, poměr např. 2-3 : 1, a nechat kompresor zabírat zejména při hlasitějších pasážích - kdy se jeho reakce zlehka projeví v cca jedné třetině stupnice gain reduction. Proto je vždy užitečné požádat interpreta, aby nám zazpíval nějakí dynamicky silné místo, zvlášť pokud interpret zkouší mikrofon polohlasným „raz, dva tři“.. Tady odkazuji na souvislost s dílem 87, kdy jsme řešili nastavení vstupní úrovně - gainu: „Často se jedná o nezkušenost zejména mladých interpretů, proto se v tomto případě nebojme při zvukovce malinko (slušně) zasáhnout: ‚takhle budeš zpívat?‘, ‚zazpívej tak, jak budeš zhruba zpívat‘, ‚ukaž mi nějaké hlasité místo - pasáž‘ atd.“ Pokud nastavíme kompresi na nízký signál a zpěvák pak následně začne zpívat výrazně hlasitěji, kompresor začne v tu chvíli redukovat (silnější) signál mnohem víc (na stupnici gain reduction bude signalizovaná větší míra komprese - bude prostě „svítit více GR LED diod“ na stupnici či na displeji). Pokud kompresi v tomto momentě ubereme (zvýšíme práh citlivosti - úroveň threshold - kompresor zabírá méně), naroste celková hlasitost signálu, tedy se dočkáme podobného efektu, jako bychom v podstatě přidali vstupní úroveň gainu. Pokud bychom v tuto chvíli gain skutečně přidali, tak tím pádem více „nakrmíme“ takto nastavený kompresor.
Pokud řídíme z FOH (hlavní mix - front of house) i monitory, pak záleží na tom, z jakého bodu vstupního řetězce signál do monitorů posíláme. Pokud jej odesíláme až za kompresí (případ starších nebo levnějších analogových pultů, kdy se signál do monitorových auxů odesílal sice před faderem, ale až za insertem, ve kterém byl zapojen kompresor, a za korekcemi), pak se nám stejný efekt jako v PA projeví i v monitorech. U této varianty odbočení signálu do monitorů jsme nuceni většinou pracovat s celkově menší mírou komprese, protože kompresor má v konečném důsledku tendenci zesilovat „tichá“ místa (tím, že nám v daném poměru zeslabí místa hlasitá, a my proto přidáme celkově výstupní úroveň, zesílí se nám logicky i tichá místa pod prahem záběru threshold), tím pádem se může zvyšovat náchylnost ke zpětné vazbě z monitorů. Nehledě k tomu, že zpěváci potřebují v monitoru většinou slyšet přímou odezvu na svůj hlas. Tedy jednoduše řečeno, když „zaberou“, chtějí, aby se signál do monitoru taktéž adekvátně zesílil, ne aby toto zesílení víceméně „požral“ kompresor. Co se v PA systému může jevit pro celkový zvuk jako ideální, nemusí být zrovna nejvhodnější pro pocit zpěváka před monitorem na pódiu. Na dnešních digitálních pultech se pro odbočení signálu do monitorů využívá nejčastěji pozice označená např. jako PRE 1, kdy signál odchází za gainem, ještě před korekcemi, kompresorem a samozřejmě před faderem.
Podotýkám, že kompresorem samotným a jeho funkcí se budeme ještě v budoucnu podrobněji zabývat. Příště pokračujeme.