Dnes se podíváme na techniku nahrávání, která zajistí, že hlavní zpěv (nebo sólový nástroj) bude mít plnější, tlustší zvuk. Lépe se tak prosadí v mixu, bude barevnější a zajímavější.

Jedná se o techniku, která se už používá vážně hóóódně dlouho (například už ABBA ji ve svých nahrávkách používala). Jednoduše řečeno, jde o zdvojování signálu hlavního zpěvu. Zní to jednoduše. Daný part prostě nahrajeme a nazpíváme několikrát přes sebe a pak je všechny přes sebe smícháme a necháme znít. Skvělé, tak se do toho pusťme!
Předtím ale ještě přece jenom jedna drobná poznámka: Pozor, nepleťme si tuto techniku s nahráváním jednoho partu několikrát, abychom si z těchto vícero záznamů nakonec vybrali jeden, ten nejlepší, anebo si z těchto vícero záznamů pomocí střihů poskládali jeden výsledný skvělý záznam (tzv. takey a následně comping). Nicméně tady už by nám mohlo trošičku svitnout, v čem bude problém.
Připravíme tedy deset stop a budeme nahrávat refrén našeho songu desetkrát po sobě, vždy do nové stopy. Na rozdíl od ve výše uvedeném nahrávání takeů zde opravdu potřebujeme deset samostatných stop, protože nakonec budeme vše míchat dohromady. Máme tedy nahraných deset verzí refrénu a můžeme si je poslechnout. A tu náhle zjistíme, že nejsme „božský Kája“. V nejhorším případě nám chybí výraz, intonace i rytmus. Pokud nám ale přece jenom bylo trochu něco dáno, alespoň trochu od každého v nahrávce přece jenom je. A s tím už se dá pracovat.
Zapracovat do DAW software na intonaci je dnes asi to nejjednodušší. Buď používáme na doladění Melodyne anebo nástroj integrovaný přímo uvnitř DAW (v Cubase je to VariAudio).
Na druhé straně škály je výraz. S tím se něco dělá jen velmi obtížně. Samozřejmě, můžeme přidat/ubrat hlasitost v určitých místech, můžeme přidat efekt atd., ale výraz a lidskost nahrávce uměle jen tak nedodáme. Na tom tedy budeme muset zapracovat sami na sobě.
Ale my se dnes budeme věnovat právě tomu poslednímu, a to je nepřesný rytmus. Jakmile si totiž poslechneme oněch deset záznamů pod sebou všechny najednou, obvykle zjistíme, že ten rytmus nemáme úplně stoprocentní. Někde jsme třeba i trošku jinak frázovali (což by už ovšem mělo být vyřešeno před nahrávkou) a někde nám to prostě ujelo. Ale je škoda mazat celý jeden záznam. A rovnat všechny záznamy ručně? Několik stop, jednu po druhé? Děkuji pěkně, to by snad za nás mohl udělat počítač, ne?
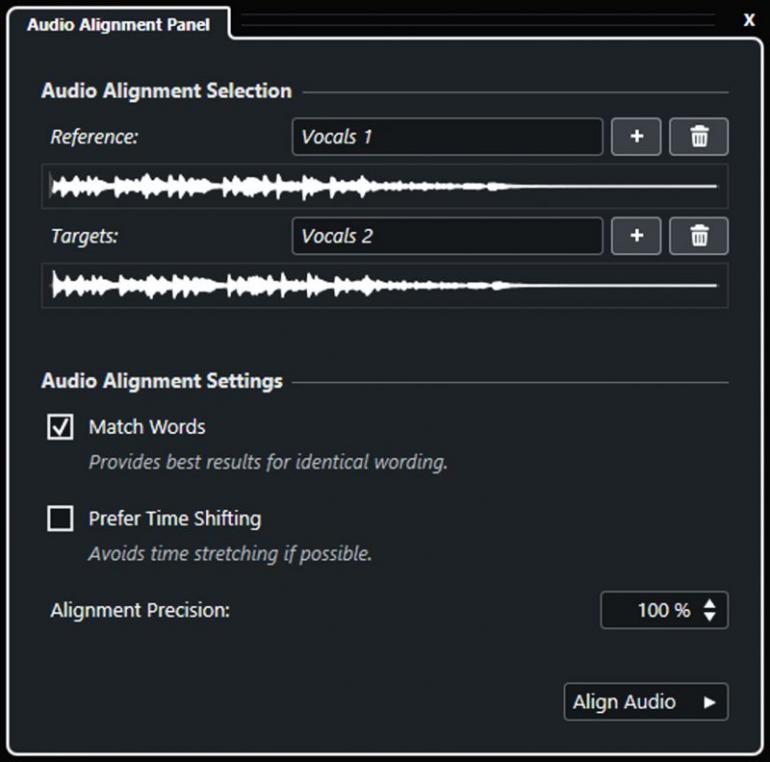
A také že udělá. Audio Alignment (srovnání/zarovnání zvuku) je funkce přesně pro nás. Audio Alignment potřebuje jednu zdrojovou zvukovou událost (Reference), tedy tu, která je rytmicky nejlepší, nejpřesnější, nejlépe odpovídá naší představě o frázování a rytmu. Tu samozřejmě můžeme předem i ručně jemně upravit, aby vše opravdu sedělo tak, jak má. A poté už můžeme jen přidat další zvukové události (Targets, může jich být označeno i více najednou), které se mají s onou zdrojovou událostí srovnat. Důležitým parametrem je Alignment Precision (přesnost zarovnání). Chceme nahrávce nechat trochu živosti, takže bych úplně nedoporučoval nastavovat na sto procent. Jakou hodnotu nastavíme, záleží samozřejmě na tom, jak moc se od sebe jednotlivé záznamy liší a jak moc je chceme „utáhnout“ k sobě. Následně pak máme ještě možnost aktivovat Match Words (srovnat slova) pro nejlepší možné zarovnání jednotlivých slov (respektive hlášek) pod sebe. Anebo naopak aktivovat možnost Prefer Time Shift, což se hodí zejména pro případ, kdy chceme srovnat jedinou nahrávku pořízenou vícero mikrofony a vlastně řešíme jen jejich fázové posunutí. A pak už jen stačí kliknout na Align Audio a máme hotovo.
Super, to bylo snadné! Ale proč vlastně nepoužijeme jen jednu perfektní nahrávku a tu lehce neposuneme v čase pomocí parametru (nikoliv plug-inu) Delay nebo Shift? Jednoduše proto, že výsledek prostě není tak dobrý, jako když to nahrajeme vícekrát. V případě pouhého posunutí je ladění vždy přesně stejné, frázování přesně stejné, a tak se celý požadovaný efekt tlustšího zvuku nedostaví. Díky za Audio Alignment.